How many Chinese characters and words are in use?
To answer a few burning questions I have about Chinese (oh, how they burn), I’ve parsed the Google ngrams data for simplified Chinese. I use the parsed data to assist in tagging sentences from my Chinese language-learning software, Outspoken.
I focus here on 1-grams, meaning whole Chinese words. This doesn’t mean words of just one character – on the contrary, many Chinese words are composed of multiple characters. For example, 希望 xiwang “to hope”, is a 1-gram made of two characters. The 1-grams dataset is small: 61MB gzipped, so it’s easy to analyze the set yourself. By comparison, the 5-grams dataset, which I’ve also parsed, is over 50GB.
We want to look at words in recent, common use. Between 2000 and 2009, Google parsed 9,786,524,890 1-grams across a total of 94,933 books. At almost ten billion parsed ngrams, I think it’s safe to filter the dataset to only include 1-grams that appear at least 1000 total times in books published during those years. After cleaning out English words, and ngrams that were missing parts of speech, I ended up with a total of 41,513 tagged simplified Chinese ngrams.
How many common words are there?
26,767 words.
Even though there are 41,513 ngrams, the vocabulary is fewer because an ngram will crop up in multiple senses. It’s quite common in Chinese for a word to exist in numerous forms. For example, 報告 baogao can mean “to report” and also the physical “report” itself.
After accounting for different forms, we end up with the above number. That seems reasonable, in light of the Economist report that an average adult native English speaker knows somewhere between 20,000 and 35,000 words.
How many characters make up common words?
3848 unique characters.
If you learned one character a day, it’d take you ten-and-a-half years to learn them all. Increase that to an aggressive twenty characters per day (which is not, by the way, the right way to learn Chinese), and you’re down to six-and-a-half months.
How many characters make up the top X%?
Also posed as, “How many characters can I get away with learning?” Here’s a cumulative distribution of characters.
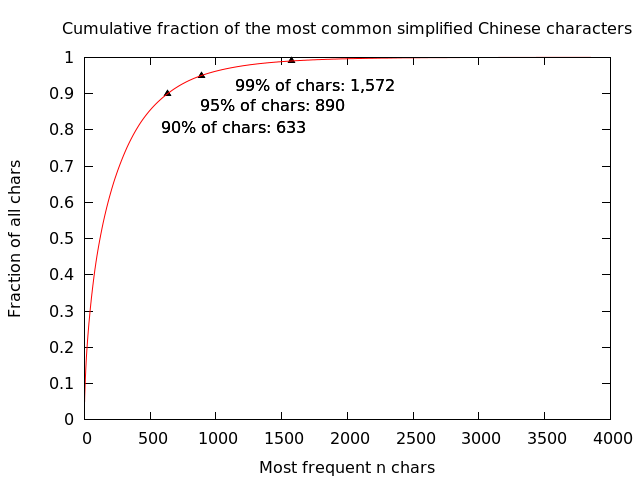
Cumulative fraction of chars --- Percentile # chars 50 119 80 393 90 633 95 890 96.2 1,000 99.0 1,572 99.9 2,565
I think this is quite encouraging! By learning only the top 1000 characters, you’ll at least be able to physically read about 96% of written Chinese.
How many words make up the top X%?
“How many words can I get away with learning?” Here’s a cumulative distribution of words.
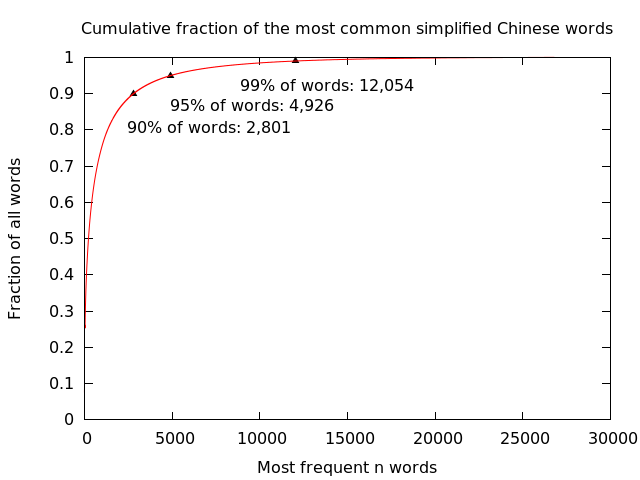
The HSK, Mainland China’s proficiency exam, tests 5000 words at level six, the highest. If you master that level (supposedly after about 3000 classroom hours), in the best case you’ll know roughly 95% of commonly used words.
Cumulative fraction of words --- Percentile # words 50 230 80 1,319 90 2,801 95 4,926 95.1 5,000 99.0 12,054 99.9 21,875
What are the most and least common words?
Most common
---
(% of total)
的 possession particle 7.7%
是 to be 1.3%
在 to be located 1.3%
了 past tense particle 1.2%
和 and 1.1%
年 year 0.9%
一 one 0.8%
有 to have 0.7%
中 middle 0.6%
这 this 0.6%
人 person 0.6%
Note: 中 zhong “middle” is probably ranked so highly because it forms part of anything related to 中国 zhongguo “China” (lit. Middle Kingdom). Google’s data source is all simplified Chinese material, mostly used in mainland China.
Least common --- 共度 to spend an occasion together 南辕北辙 to defeat one's own purpose (idiom) 补益 benefit (formal) 済 cross a river 娘子军 female military regiment 配餐 catering 较真 in earnest 洗脑 to brainwash 死去活来 to straddle life and death (idiom) 双休日 two-day weekend
Note: I omitted a few names of famous people.
May I have the dataset?
Here are the data files and graph scripts. I’d love to hear of any analysis you do with it. Send me an email (top-right)!
